Over the past few months, autoresearch has started evolving from an intriguing idea into a workable engineering paradigm. Karpathy’s autoresearch[1]laid out a clear direction: let agents not just answer questions, but propose experiments, run training, read results, and move on to the next round. Similar ideas have appeared in work more focused on algorithmic search and heuristic learning — for example, OpenAI’s Parameter Golf[2], and experiments using agents to discover interpretable heuristic policies in physics simulation environments[3],[4]. Cursor’s Composer series has also been hammering the same point: a truly useful agent shouldn’t just perform well on static benchmarks — it should be able to continuously complete complex tasks inside a harness that approximates a real working environment[5],[6].
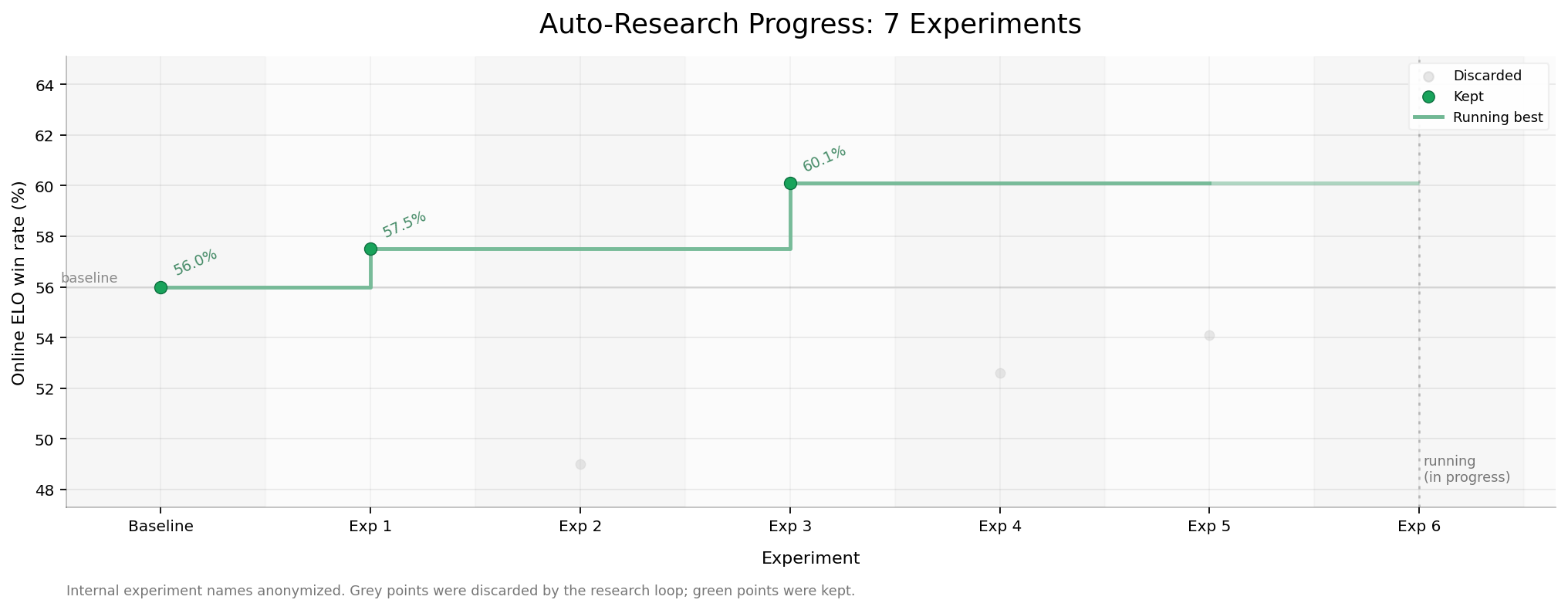
We connected this loop to real online traffic. Two days, 7 SFT experiments, online preference win rate 56.0% → 60.1%. Data filtering, training, deployment, online ELO evaluation, and next-experiment decisions — all in the same loop.
Offline evaluation isn’t enough
Initially, we also kept common offline signals: training loss, validation loss, fixed case judges, general benchmarks, and so on as auxiliary signals. These signals are useful, but fundamentally fail to align with the primary online objective — and actually interfere with the model’s decision-making, because the model is extremely prone to misattribution.
In conversational models, user preference often comes from very fine details: tone, pacing, response length, whether the model picks up context, whether the user wants to keep chatting. Many offline metrics are insensitive to these differences. Loss can help select checkpoints, but it can barely tell us which data distribution works better for online users.
So we ultimately kept only online evaluation, using online ELO: users make preference choices between two model outputs in real product traffic. The agent decides whether to keep or discard an experiment based on win rate, sample count, and convergence.
The benefit of ELO is that it’s simple and direct: every candidate model enters the same real online traffic pool, users choose between two responses, and the system aggregates those choices into a comparable win rate. The agent gets the signal of which response real users actually prefer.
When evaluation, data selection, and training decisions are all anchored to the same online distribution, the agent’s entire iteration process becomes on-policy. Every judgment comes directly from, and acts directly upon, the real deployment environment.
Autoresearch harness
Our product is a consumer AI-native content platform with millions of DAU, with a built-in arena-style online evaluation system: users make preference choices between two model responses during real usage, and the system continuously aggregates these choices to compute ELO for each candidate model. We have a natural, high-frequency online reward signal that plugs directly into the agent’s research loop.
The hardware scale wasn’t extravagant: a single 8×H100 machine, training a Gemma 4. Each experiment was constrained to a fixed budget, rather than letting the agent freely scale up training. Default setup:
- Single node, 8×H100
- Fixed data budget
- Fixed training recipe
- Fixed online ELO evaluation protocol
- Each experiment changes only one primary variable
This constraint matters. Without budget boundaries, autoresearch easily degenerates into automated grid search: the agent tries more steps, more data, more parameters, and ends up with results that are impossible to attribute. The harness is designed to keep each round cheap enough, while making every variable change explainable.
The harness provides a set of controlled interfaces that let the agent safely compose research actions:
- Data interface: filter, sample, and split training data
- Training interface: fix the training process within a comparable budget
- Deployment interface: plug candidate models into the internal serving and evaluation stack
- Evaluation interface: submit for online ELO, read aggregated metrics
- Memory interface:persist last round’s conclusions, research constraints, and next-round plans
- Cleanup interface: stop experiments, release resources, clean up temporary configurations
The agent can propose hypotheses, change training distributions, and launch experiments, but it can’t arbitrarily change all variables.
The full loop is:
fetch raw data → filtering → fixed-budget sampling → SFT training → candidate deployment → online ELO evaluation → result aggregation → next experiment
The memory layer records current experiment constraints, validated judgments, interim hypotheses, and next-round plans, so the agent doesn’t rely solely on immediate context during long loops. New research ideas are first recorded as hypotheses, then translated into data filters, training configs, or evaluation experiments. Even if a long task is interrupted, the agent can resume its current direction from these persisted constraints and plans.
What the agent discovered
Scheduling.If every round ran sequentially — train → deploy → eval → analyze → next train — the entire autoresearch loop would be very slow. Online evaluation needs to wait for real traffic, deployment has cold starts, and you can’t let local training resources sit idle. After multiple rounds, the agent gradually settled into a one-step-off scheduling pattern:
- GPU lane: train experiment N
- Network lane:prepare / upload experiment N−1
- Remote lane:deploy + online eval experiment N−1
- CPU lane:analyze experiment N−2 + prepare N+1
A single experiment from training to usable online signal can typically be kept to the order of just over an hour. If the agent frequently sits idle, it can’t sustain research progress.
“Dirtier” data wins.Intuitively, we usually assume: if you use a stronger expert model to generate training data, the student model should learn better. Expert model responses are more stable, cleaner, with fewer mistakes — they seem better suited as a teacher.
But in online ELO, the agent compared win rate curves of candidate models trained on different data sources and observed a counterintuitive result: fine-tuning with a relatively less “expert” data source actually outperformed using stronger, cleaner expert data.
While analyzing training data and online results, the agent itself proposed a hypothesis: this “weaker” data source had more heterogeneous historical context. Its conversation history contained responses from different models at different stages, making it more like the real online runtime environment; the expert model’s data was relatively cleaner and more self-consistent, but also more like a closed distribution.
This hypothesis changed the direction of subsequent experiments: Experiment 1 looked higher quality but didn’t produce online improvement; Experiment 2’s teacher wasn’t necessarily stronger, but its history distribution was closer to real product traffic; Experiment 3 further amplified this signal and became the best result of the iteration. In other words:
The agent improved the model by discovering a better training distribution, not by tuning hyperparameters.
This aligns with our intuition about model research. For an already strong base model, whether fine-tuning is effective often depends on what data you give it and whether that data truly matches the deployment context distribution — not on how finely you sweep the hyperparameter grid.
What’s next
More real-time online evaluation.Both ELO and Session A/B are real online feedback, but the feedback cycle is still on the longer side. ELO needs to accumulate enough user choices — often a single judgment takes tens of minutes to hours. The next step is ideally to build a more real-time online evaluation system: still derived from real users or real product behavior, but able to produce stable, usable local signals faster. This way the agent’s research loop can be compressed from “a few hours per round” to “tens of minutes per round.”
On-policy data flywheel.Currently, training data comes from cleaning historical conversations — it is not on-policy data sampled by the model being trained. The next step is to let the deployed model use its own real interaction data directly as input for the next training round — each iteration’s training distribution isthe deployment distribution. Better model, higher quality online interactions, better training data, better model. Cursor’s Tab RL[8] and Real-Time RL for Composer[9] have already validated similar on-policy loops in code completion and multi-file editing.
Closing
Dario Amodei once described strong AI as a “country of geniuses in a datacenter”[7]. If that era is coming, then what truly matters is not just how smart the models are, but whether we can build good enough harnesses for these agents: letting them access real feedback, follow experiment constraints, accumulate long-term memory, and translate capability into verifiable progress.
This experiment let us see clearly: when an agent is connected to a real research loop, it starts not just writing code, but running research.
If you’re interested in this problem too, come join us.
References
- Andrej Karpathy, autoresearch.
- OpenAI, Parameter Golf.
- Paul Garnier-Muller, Heuristic Learning for Fluid Dynamics: A Case Study.
- trinkle23897, Learning Beyond Gradients.
- Cursor Team, Introducing Composer 2.5.
- Sasha Rush / Cursor, A technical report on Composer 2.
- Dario Amodei, The Adolescence of Technology.
- Cursor Team, Tab RL.
- Cursor Team, Real-Time RL for Composer.