过去一段时间,Autoresearch 开始从一个有趣的想法变成可运行的工程范式。Karpathy 的 autoresearch[1] 展示了一个很清楚的方向:让 agent 不只是回答问题,而是自己提出实验、运行训练、读取结果,然后继续下一轮。类似的想法也出现在一些更偏算法搜索和启发式学习的实验里,例如 OpenAI 的 Parameter Golf[2],以及用 agent 在物理仿真环境中寻找可解释 heuristic policy 的案例[3],[4]。Cursor 的 Composer 系列也在反复强调同一件事:真正有用的 agent,不应该只在静态 benchmark 上表现好,而应该能在接近真实工作环境的 harness 里持续完成复杂任务[5],[6]。
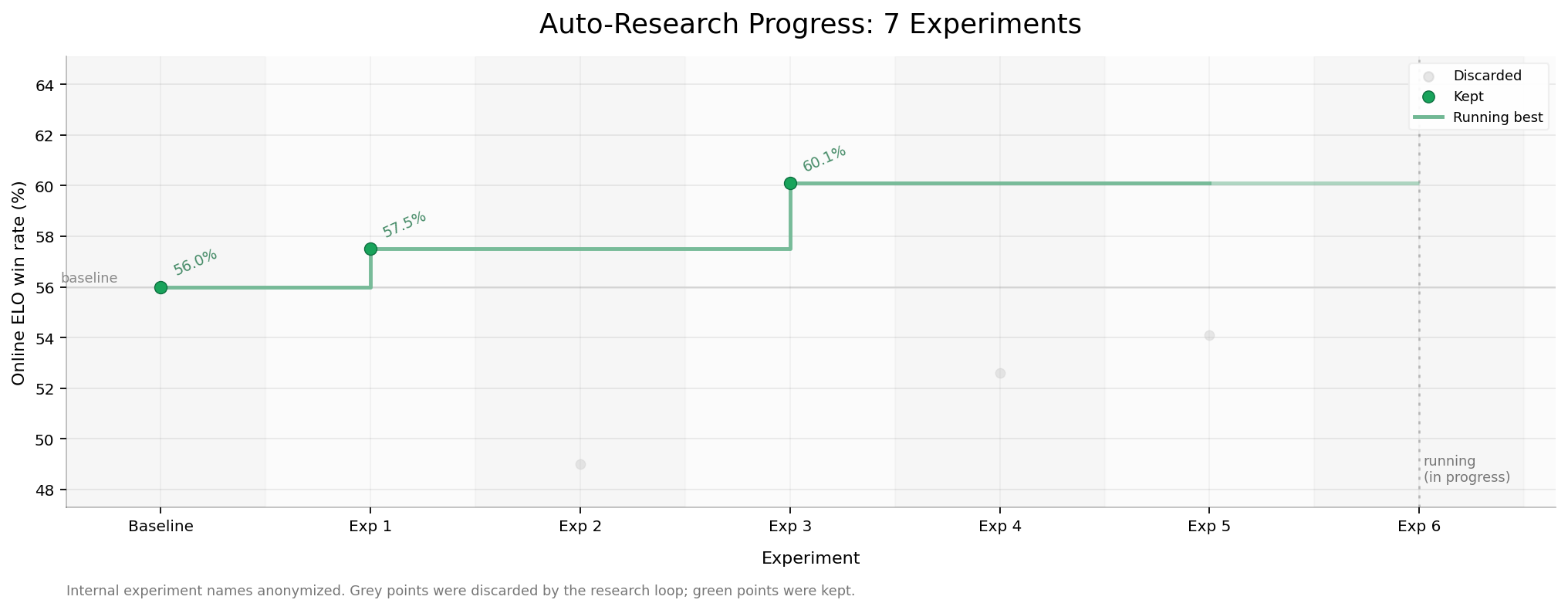
我们把这个 loop 接到了真实线上流量上。两天,7 个 SFT 实验,线上偏好胜率 56.0% → 60.1%。从数据过滤、训练、部署,到线上 ELO 评估和下一轮实验决策,全在同一个 loop 里完成。
离线评估不够用
最开始,我们也保留了常见的离线信号:training loss、validation loss、固定 case judge、通用 benchmark 等作为辅助信号。这些信号有用,但根本无法与线上主要目标对齐,反而会干扰模型决策,因为模型非常容易发生错误归因。
在对话模型里,用户偏好经常来自很细的东西:语气、节奏、回复长度、是否接住上下文、是否让用户愿意继续聊。很多离线指标对这些差异不敏感。loss 能帮助选择 checkpoint,但很难告诉我们哪个数据分布更适合线上用户。
所以我们最终只保留线上评估,使用线上 ELO:用户在真实产品流量里对两个模型输出做偏好选择。agent 根据胜率、样本数、收敛情况决定一个实验是 keep 还是 discard。
ELO 的好处是简单直接:每个候选模型都进入同一个真实线上流量池,用户在两个回复之间做选择,系统把这些选择聚合成一个可比较的 win rate。agent 拿到的是“真实用户更愿意选择哪个回复”的信号。
当评估、数据选择、训练决策都锚定在同一个线上分布上时,agent 的整个迭代过程变成了 on-policy 的。每一步判断都直接来自、也直接作用于真实部署环境。
Autoresearch Harness
我们的产品是一个百万 DAU 级别的 C 端 AI 原生内容平台,内置 arena-style 在线评估系统:用户在真实使用中对两个模型的回复做偏好选择,系统持续聚合这些选择为每个候选模型计算 ELO。我们有一个天然的、高频的线上 reward signal,可以直接接入 agent 的研究循环。
硬件规模并不夸张:一台 8 卡 H100 机器,训练一个 Gemma 4。每次实验都被限制在一个固定预算里,而不是让 agent 自由扩大训练规模。默认设置:
- 单机 8×H100
- 固定数据预算
- 固定训练 recipe
- 固定线上 ELO 评估方式
- 每个实验只改变一个主要变量
这个约束很重要。Autoresearch 如果没有预算边界,很容易退化成自动 grid search:agent 会尝试更多步数、更大数据、更多参数,最后得到一个难以归因的结果。harness 的设计目标是:把每轮实验压到足够便宜,同时让每个变量变化都可以解释。
harness 提供一组受控接口,让 agent 能安全地组合研究动作:
- Data interface:过滤、采样、切分训练数据
- Training interface:把训练过程固定在一个可比预算内
- Deployment interface:把候选模型接入内部 serving 和 evaluation stack
- Evaluation interface:提交线上 ELO,读取聚合指标
- Memory interface:把上一轮结论、研究约束和下一轮计划持久化下来
- Cleanup interface:停止实验、释放资源、清理临时配置
agent 可以提出假设、改变训练分布、启动实验,但它不能随便改所有变量。
完整的 loop 是:
fetch raw data → filtering → fixed-budget sampling → SFT training → candidate deployment → online ELO evaluation → result aggregation → next experiment
Memory 层记录当前实验约束、已验证的判断、阶段性假设和下一轮计划,让 agent 在长循环里不只依赖当下上下文。新的研究想法先作为假设被记录,再被转成数据过滤、训练配置或评估实验。即使一次长任务被打断,agent 重新进入项目后,也能从这些持久化的约束和计划里恢复当前方向。
Agent 发现了什么
调度。如果每轮都按顺序执行 train → deploy → eval → analyze → next train,整个 Autoresearch 会非常慢。线上评估需要等待真实流量,部署也有冷启动,不能让本地训练资源一直空等。在多轮尝试之后,agent 逐渐沉淀出一种 one-step-off scheduling:
- GPU lane:train experiment N
- Network lane:prepare / upload experiment N−1
- Remote lane:deploy + online eval experiment N−1
- CPU lane:analyze experiment N−2 + prepare N+1
单个实验从训练到拿到可用线上信号,通常可以控制在一个多小时的量级。agent 如果经常空等,就很难持续产生研究进展。
更“脏”的数据更好。直觉上,我们通常会认为:如果用一个更强的专家模型生成训练数据,学生模型应该学得更好。专家模型的回复更稳定、更干净、更少犯错,看起来也更适合作为 teacher。
但在线上 ELO 里,agent 对比了不同数据源训练出的候选模型的胜率曲线,观察到一个反直觉结果:用一个相对没那么“专家”的数据源微调,反而比用更强、更干净的专家数据更好。
agent 在分析训练数据和线上结果时,自己提出了一个假设:这个“较弱”数据源的历史上下文更混杂。它的 conversation history 里混有不同模型在不同阶段产生的回复,因此更像真实线上运行时的环境;而专家模型的数据相对更干净、更自洽,但也更像一个封闭分布。
这个假设改变了后续实验方向:实验 1 看起来质量更高,却没有带来线上提升;实验 2 的 teacher 本身未必更强,但它的 history distribution 更接近真实产品流量;实验 3 在这个方向上继续放大了信号,最终成为这轮迭代里最好的结果。换句话说:
The agent improved the model by discovering a better training distribution, not by tuning hyperparameters.
这和我们对模型研究的直觉是一致的。对一个已经很强的 base model 来说,微调是否有效,往往取决于你给它什么数据,以及这些数据是否真的匹配部署时的上下文分布,而不是把超参网格扫得多细。
下一步
更实时的在线评估。ELO 和 Session AB 都是真实线上反馈,但反馈周期仍然偏长。ELO 需要积累足够多用户选择,很多时候一次判断要几十分钟到几个小时。下一步更理想的是构建更实时的在线评估系统:仍然来自真实用户或真实产品行为,但能更快地产生稳定、可用的局部信号。这样 agent 的 research loop 可以从“几个小时一轮”进一步压缩到“几十分钟一轮”。
On-policy 数据飞轮。目前训练数据来自历史对话清洗,不是被训练模型自身采样的 on-policy 数据。下一步是让部署模型直接用自己产生的线上交互数据作为下一轮训练输入——每一轮迭代的训练分布就是部署分布。模型越好,线上交互质量越高,训练数据越好,模型更好。Cursor 的 Tab RL[8] 和 Real-Time RL for Composer[9] 已经在代码补全和多文件编辑场景里验证了类似的 on-policy 闭环。
结语
Dario Amodei 曾把强 AI 称为一个 “country of geniuses in a datacenter”[7]。如果那个时代正在到来,那么真正重要的不只是模型本身有多聪明,而是我们能否为这些 agent 构建足够好的 harness:让它们接触真实反馈,遵守实验约束,积累长期记忆,并把能力转化成可验证的进步。
这次实验让我们清楚地看到:当 agent 被接入真实研究循环时,它开始不只是写代码,而是在运行研究。
如果你也对这个问题感兴趣,请加入我们!
参考文献
- Andrej Karpathy, autoresearch.
- OpenAI, Parameter Golf.
- Paul Garnier-Muller, Heuristic Learning for Fluid Dynamics: A Case Study.
- trinkle23897, Learning Beyond Gradients.
- Cursor Team, Introducing Composer 2.5.
- Sasha Rush / Cursor, A technical report on Composer 2.
- Dario Amodei, The Adolescence of Technology.
- Cursor Team, Tab RL.
- Cursor Team, Real-Time RL for Composer.